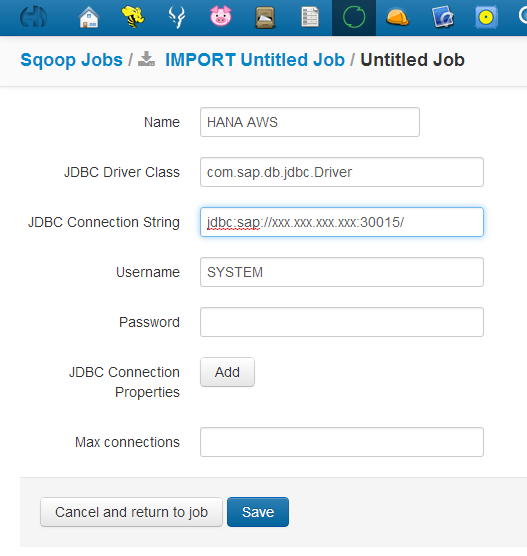
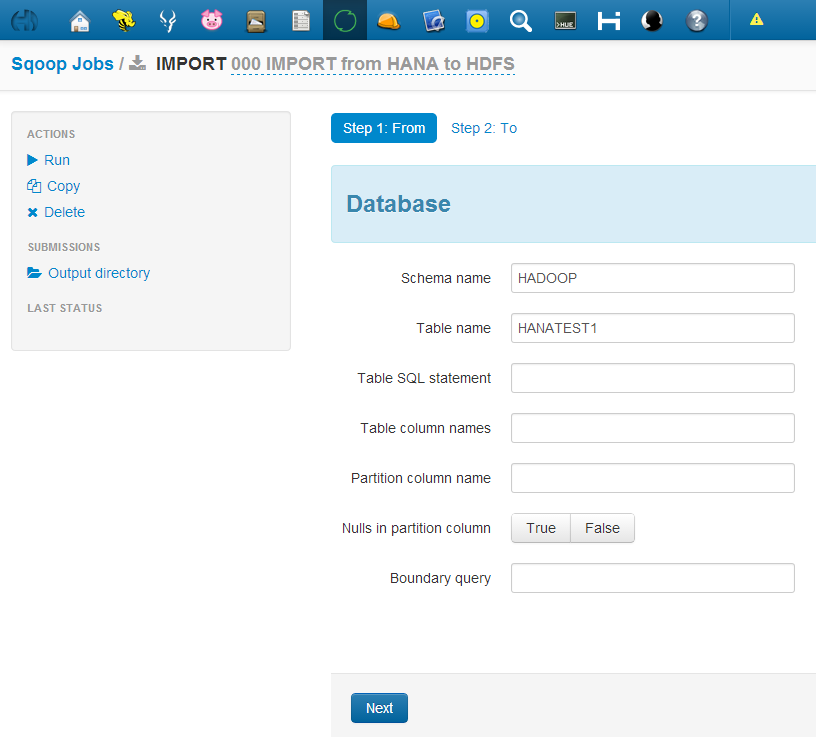
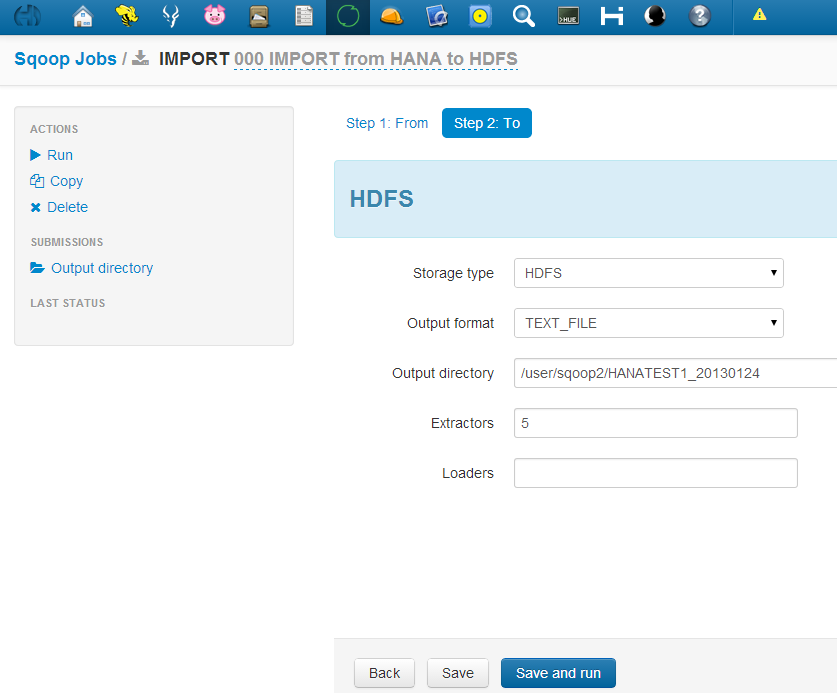
There are several standard ways that HANA Procedures can be scheduled:
e.g:
1) HANA SPS7 XS Job Scheduling (Job Scheduling | SAP HANA)
2) SAP DataService (How to invoke SAP HANA stored procedures from D... | SAP HANA)
For those that use opensource HADOOP for managing Big Data, then OOZIE can also be used to execute HANA procedures in a workflow.
For a good overview of HADOOP terms and definitions please refer to:
SAP HANA - Hadoop Integration # 1
A Big Data workflow integrating HADOOP and HANA might be:
Image may be NSFW.
Clik here to view.
The focus on the remaining part of this blog is only to demonstrate how HANA Server Side Java script (XSJS) can be used to execute HANA procedures [ point d) in diagram above] via an OOZIE WorkFlow:
Oozie is currently described in Wikipedia as
" a workflow scheduler system to manage Hadoop jobs. It is a server-based Workflow Engine specialized in running workflow jobs with actions that run Hadoop MapReduce and Pig jobs. Oozie is implemented as a Java Web-Application that runs in a Java Servlet-Container.
For the purposes of Oozie, a workflow is a collection of actions (e.g. Hadoop Map/Reduce jobs, Pig jobs) arranged in a control dependency DAG (Direct Acyclic Graph). A "control dependency" from one action to another means that the second action can't run until the first action has completed. The workflow actions start jobs in remote systems (Hadoop or Pig). Upon action completion, the remote systems call back Oozie to notify the action completion; at this point Oozie proceeds to the next action in the workflow.
Oozie workflows contain control flow nodes and action nodes. Control flow nodes define the beginning and the end of a workflow (start, end and fail nodes) and provide a mechanism to control the workflow execution path (decision, fork and join nodes). Action nodes are the mechanism by which a workflow triggers the execution of a computation/processing task. Oozie provides support for different types of actions: Hadoop MapReduce, Hadoop file system, Pig, SSH, HTTP, eMail and Oozie sub-workflow. Oozie can be extended to support additional types of actions.
Oozie workflows can be parameterized (using variables like ${inputDir} within the workflow definition). When submitting a workflow job, values for the parameters must be provided. If properly parameterized (using different output directories), several identical workflow jobs can run concurrently. "
I think I've also read that Oozie was original designed by Yahoo (now Hortonworks) for managing their complex HADOOP workflows.
It is opensource and able to be used by all distributions of HADOOP (e.g Cloudera, Hortonworks, etc).
Ooze workflows can be defined in XML, or visually via the Hadoop User Interface (Hue - The UI for Apache Hadoop).
Below I will demonstrate a very simple example workflow of HANA XSJS being called to:
A) Delete the Contents of a Table in HANA
B) Insert a Single Record in the Table
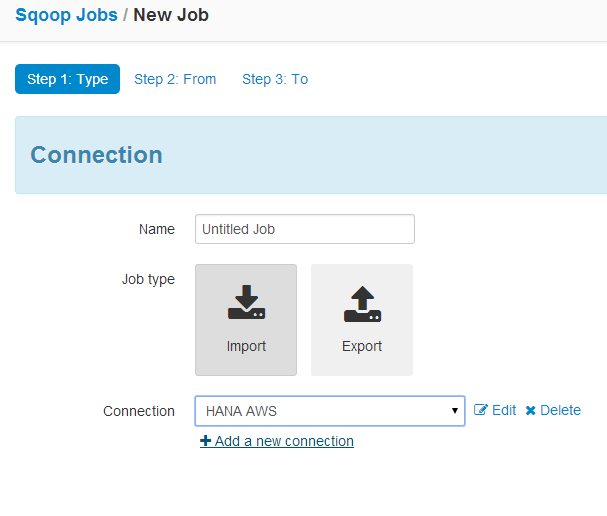
To call procedures in HANA from HADOOP I created 2 small programs:
1) in HANA a generic HANA XSJS for calling procedures (callProcedure.xsjs)
2) In HADOOP a generic JAVA program for calling HANA XSJS (callHanaXSJS.java)
The HANA XSJS program has up to 7 input parameters:
iProcedure - is the procedure to be called (mandatory)
iTotalParameters - is the number of additional input parameters used by the Procedure (Optional - default 0)
iParam1 to iParam5 - are the input parameters of the procedure.
In the body of the Reponse I provide the basic input and output info (including DB errors) in JSON format.
HANA: callProcedure.xsjs |
|---|
var maxParam = 5; var iProcedure = $.request.parameters.get('iProcedure'); var iTotalParameters = $.request.parameters.get("iTotalParameters"); var iParam1 = $.request.parameters.get("iParam1"); var iParam2 = $.request.parameters.get("iParam2"); var iParam3 = $.request.parameters.get("iParam3"); var iParam4 = $.request.parameters.get("iParam4"); var iParam5 = $.request.parameters.get("iParam5");
var output = {};
output.inputParameters = {}; output.inputParameters.iProcedure = iProcedure; output.inputParameters.iTotalParameters = iTotalParameters; output.inputParameters.iParam1 = iParam1; output.inputParameters.iParam2 = iParam2; output.inputParameters.iParam3 = iParam3; output.inputParameters.iParam4 = iParam4; output.inputParameters.iParam5 = iParam5;
output.Response = []; var result = "";
// Check inputs //if (iProcedure === '') { if (typeof iProcedure === 'undefined' ) { result = "ERROR: '&iProcedure=' Parameter is Mandatory"; output.Response.push(result); $.response.status = $.net.http.INTERNAL_SERVER_ERROR; $.response.setBody(JSON.stringify(output));
}
else {
var conn = $.db.getConnection(); var pstmt;
if (typeof iTotalParameters === 'undefined') { iTotalParameters = 0; }
var sql = "call \"_SYS_BIC\".\"" + iProcedure + "\"(";
if (iTotalParameters > 0 && iTotalParameters <= maxParam) { var i; for (i=0;i< iTotalParameters;i++) { if (i===0) { sql += "?"; } else {sql += ",?"; } } } else { if (iTotalParameters !== 0 ) { result = "WARNING: '&iTotalParameters-' Parameter shoule be between 0 and " + maxParam; output.Response.push(result); } }
sql += ")";
output.inputParameters.sql = sql;
try{ //pstmt = conn.prepareStatement( sql ); //used for SELECT pstmt = conn.prepareCall( sql ); //used for CALL
if (iTotalParameters >= 1) { pstmt.setString(1,iParam1);} if (iTotalParameters >= 2) { pstmt.setString(2,iParam2);} if (iTotalParameters >= 3) { pstmt.setString(3,iParam3);} if (iTotalParameters >= 4) { pstmt.setString(4,iParam5);} if (iTotalParameters >= 5) { pstmt.setString(5,iParam5);}
// var hanaResponse = pstmt.execute(); if(pstmt.execute()) { result = "OK:"; var rs = pstmt.getResultSet(); result += JSON.stringify(pstmt.getResultSet()); }
else { result += "Failed to execute procedure"; } } catch (e) { result += e.toString(); }
conn.commit();
conn.close();
//var hanaResponse = [];
output.Response.push(result); $.response.setBody(JSON.stringify(output)); } |
The HADOOP Java program accepts a minimum of 4 input arguments:
arg[0] - URL of a HANA XSJS, accessible via the HADOOP cluster
arg[1] - HANA User name
arg[2] - HANA Password
arg[3] - HADOOP HDFS Output directory for storing response
arg[4 to n] - are used for the input parameters for the HANA XSJS called
| HADOOP: callHanaXSJS.java |
|---|
package com.hanaIntegration.app;
/** * Calls a HANA serverside javascript (xsjs) * INPUTS: (mandatory) HANA XSJS URL, output logfile name, username & password * (optional) n parameters/arguments * OUTPUT: writes HANA XSJS response to a the logfile on HDFS * */
import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.HttpURLConnection; import java.net.URL; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;
public class callHanaXSJS { public static void main(String[] args) throws IOException {
String sUrl = args[0];
//Append XSJS Command parmeters if (args.length > 4) { //append first parameter sUrl += "?" + args[4]; //add subsequent for(int i= 5;i < args.length;i++) { sUrl += "&" + args[i]; } }
System.out.println("HANA XSJS URL is: " + sUrl); URL url = new URL(sUrl);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
String userpass = args[1] + ":" + args[2]; //args[0] user args[1] password String basicAuth = "Basic " + javax.xml.bind.DatatypeConverter.printBase64Binary(userpass.getBytes());
conn.setRequestProperty ("Authorization", basicAuth);
conn.connect(); InputStream connStream = conn.getInputStream();
// HDFS Output
FileSystem hdfs = FileSystem.get(new Configuration()); FSDataOutputStream outStream = hdfs.create(new Path(args[3], "HANAxsjsResponse.txt")); IOUtils.copy(connStream, outStream);
outStream.close();
connStream.close(); conn.disconnect(); } } |
NOTE: HADOOP Java programs are compiled as JAR's and stored on HADOOP HDFS prior to execution by OOZIE
With the small programs in place I will now show the setup in Ooozie using HUE.
Below are Screenshots from my small Hortonworks Hadoop HDP2.0 cluster running on EC2
( For setting up your own cluster or downloading a test virtual machine see HDP 2.0 - The complete Hadoop 2.0 distribution for the enterprise
Image may be NSFW.
Clik here to view.

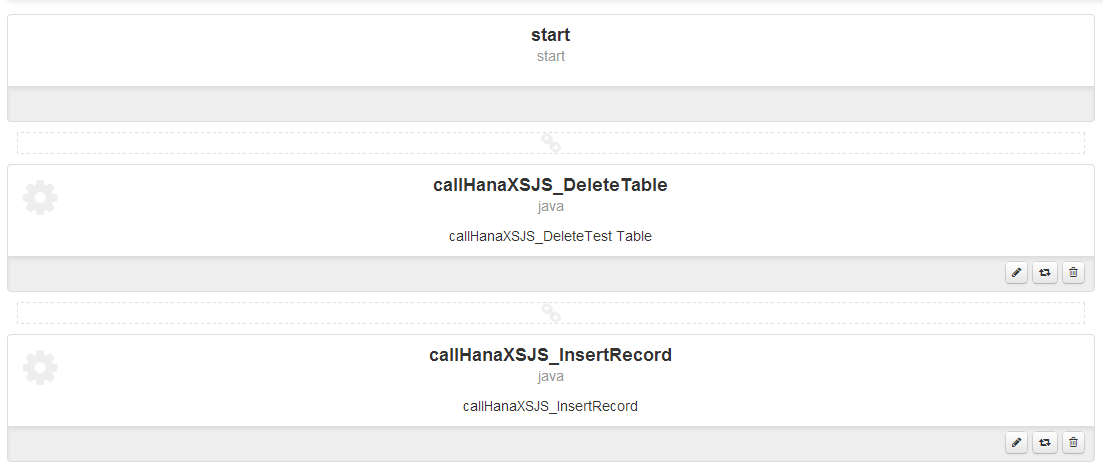
Zoomed in a bit to the 2 workflow tasks:
Image may be NSFW.
Clik here to view.
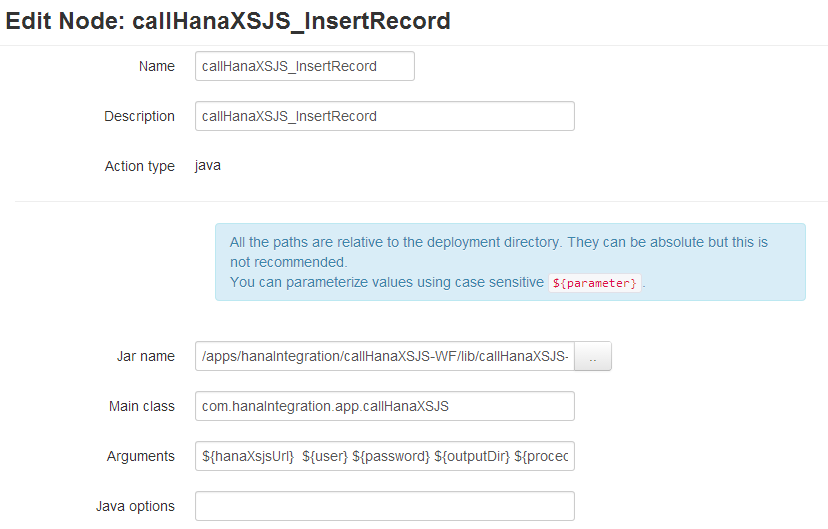
The definition of the first workflow task is:
Image may be NSFW.
Clik here to view.

Image may be NSFW.
Clik here to view.

The JAR I created was:
/apps/hanaIntegration/callHanaXSJS-WF/lib/callHanaXSJS-1.0-SNAPSHOT.jar
The arguments passed to call a delete procedure (no parameters) in HANA are:
${hanaXsjsUrl} ${user} ${password} ${outputDir} ${procedure_delete}
As this is the first task I also delete and create a directory to store the Log files of each task.
This will store the JSON return by the HANA XSJS.
The Second workflow task is:
Image may be NSFW.
Clik here to view.
The arguments passed to call an INSERT procedure (no parameters) in HANA are:
${hanaXsjsUrl} ${user} ${password} ${outputDir} ${procedure_insert} ${insertTotalParams} ${insertId} ${insertField1}
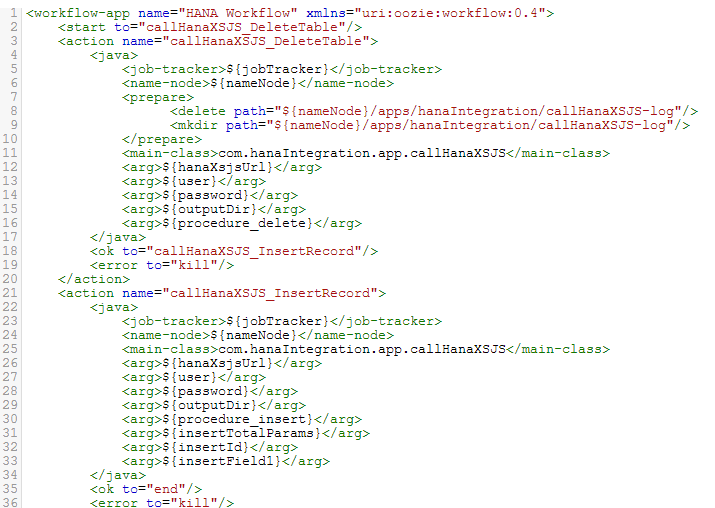
The follow XML workflow is then created at runtime:
Image may be NSFW.
Clik here to view.
I can then submit/schedule the workflow:
Image may be NSFW.
Clik here to view.

In my Test I passed the following parameters to the workflow:
(NOTE: unfortunately the order of input parameters via HUE is currently messy. If manually creating XML this can be tidied up in a more logical order
Image may be NSFW.
Clik here to view.

In a more logical sequence of this is:
Following used by both tasks
${hanaXsjsUrl}http://ec2-54-225-226-245.compute-1.amazonaws.com:8000/OOZIE/OOZIE_EXAMPLE1/services/callProcedure.xsjs
${user} HANAUserID
${password} HanaPAssword
${outputDir} hdfs://ip-xx-xxx-xx-xx.ec2.internal:8020/apps/hanaIntegration/callHanaXSJS-log
Used by Delete task
${procedure_delete} iProcedure=OOZIE.OOZIE_EXAMPLE1.procedures/deleteTestTable
Used by Insert task
${procedure_insert} iProcedure=OOZIE.OOZIE_EXAMPLE1.procedures/create_record
${insertTotalParams} iTotalParameters=2
${insertId} iParam1=10
${insertField1}iParam2=fromHADOOP
Once the Workflow runs we see the following:
Image may be NSFW.
Clik here to view.

Image may be NSFW.
Clik here to view.
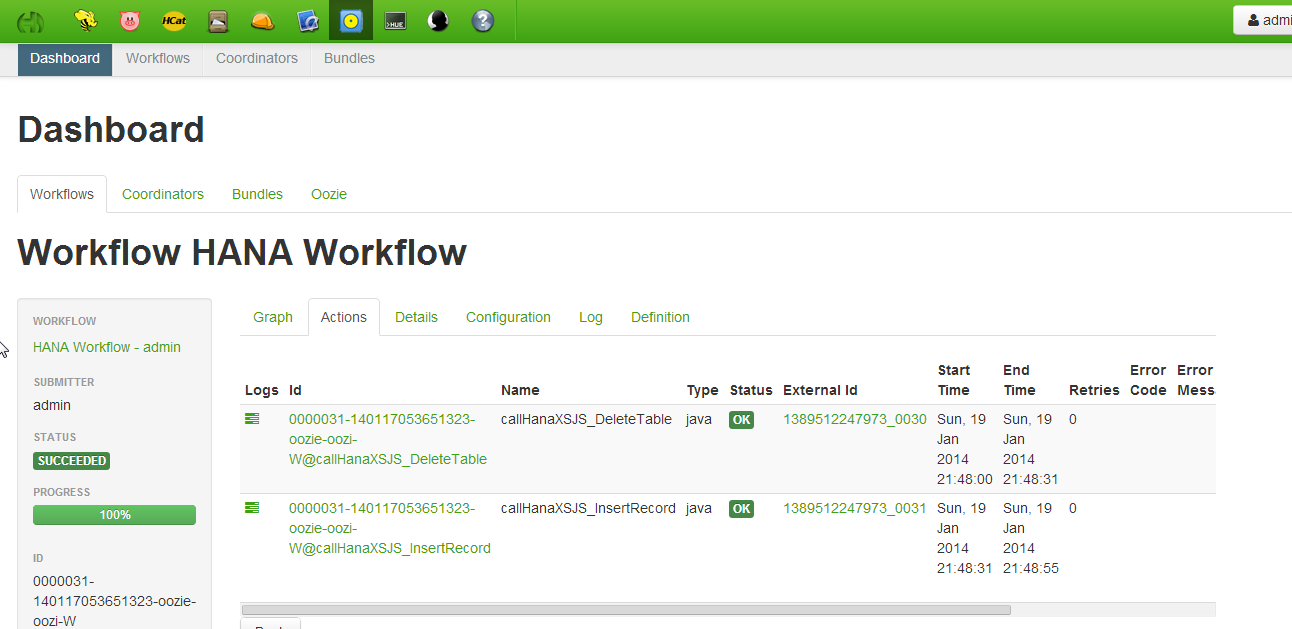
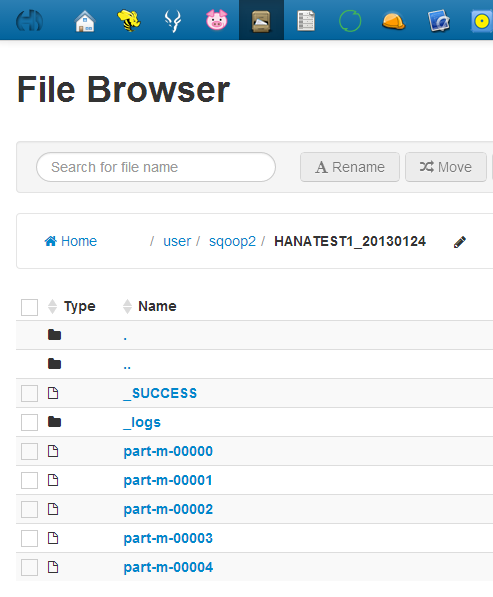
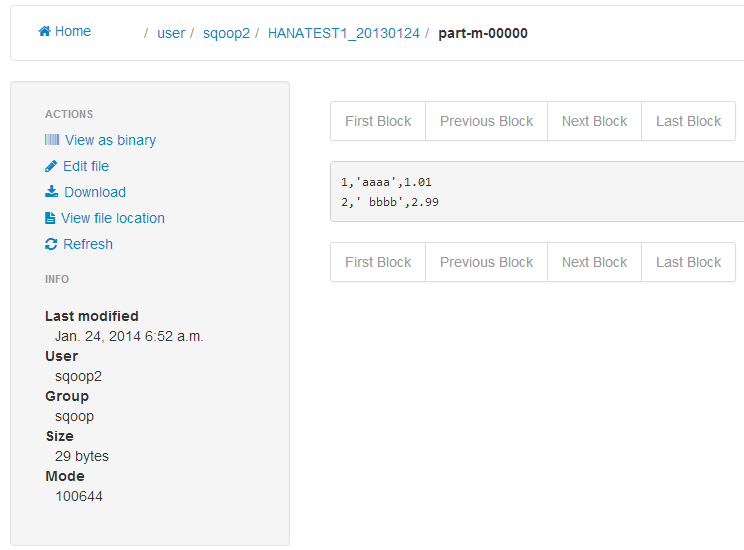
The following log files were screated by each task:
Image may be NSFW.
Clik here to view.

The Insert task Log file shows as:
Image may be NSFW.
Clik here to view.

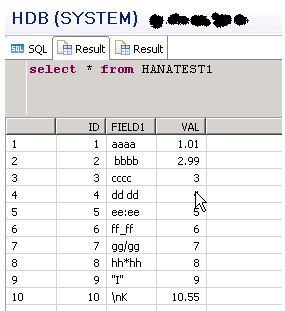
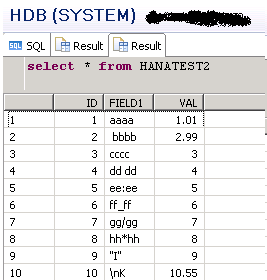
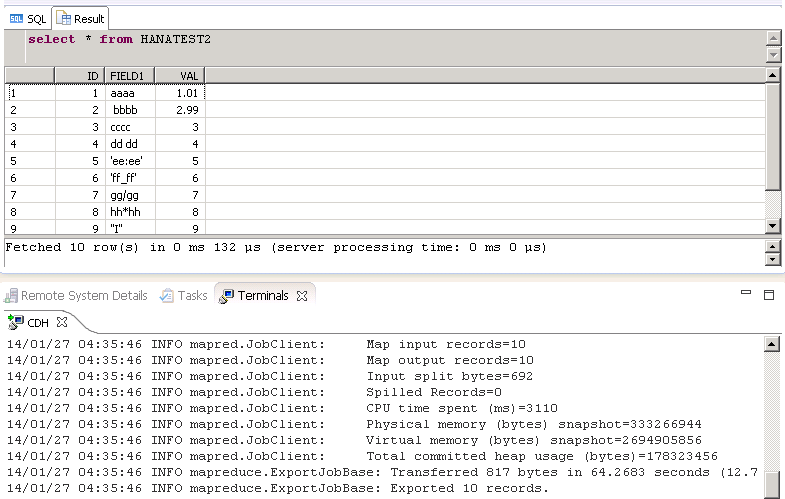
Finally we can check in HANA to confirm the record has been created:
Image may be NSFW.
Clik here to view.
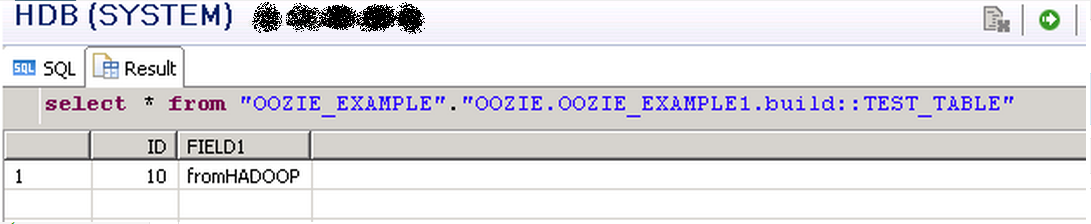
OK for inserting one record this isn't very exciting and a bit of an overkill Image may be NSFW.
Clik here to view. , but conceptually this enables the power of HADOOP and HANA to be harnessed and combined in a single workflow.
, but conceptually this enables the power of HADOOP and HANA to be harnessed and combined in a single workflow.
BTW: I'll upload my code onto Git Hub shortly for those that are interested. I welcome all comments and enhancements to my code.