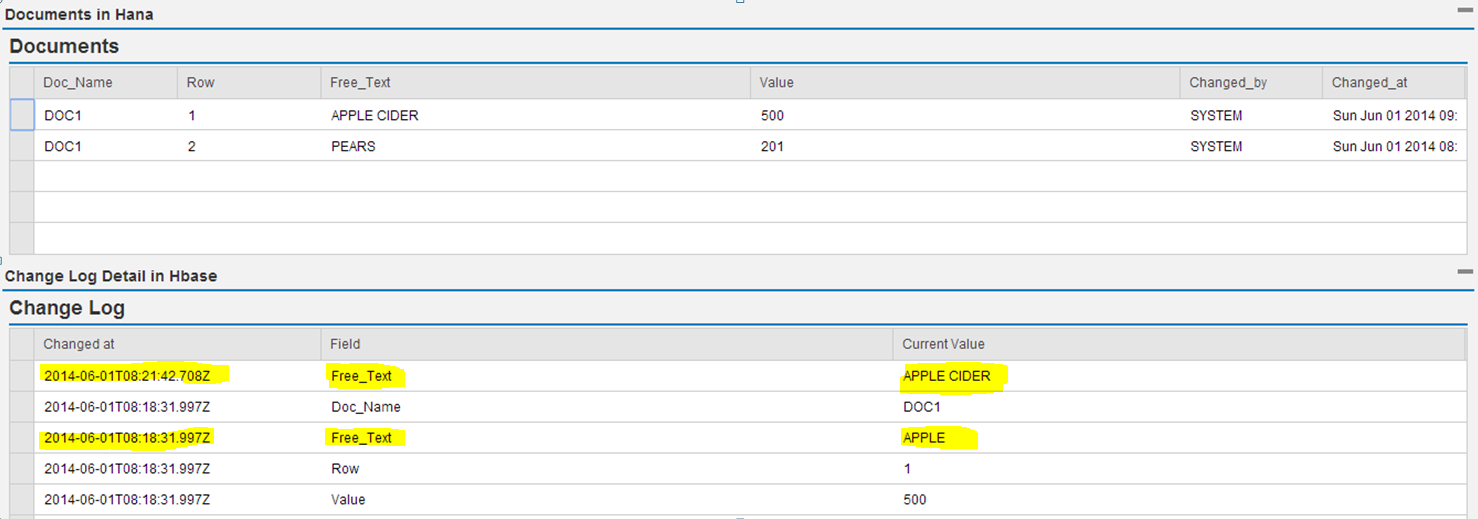
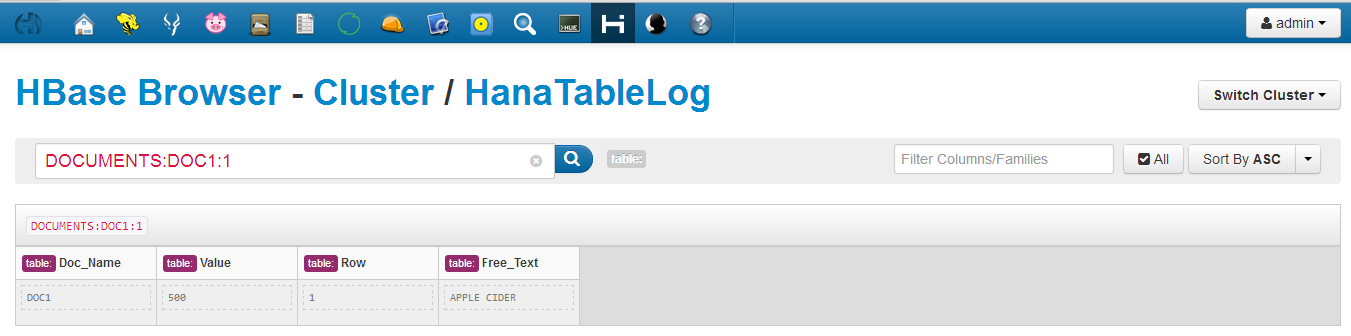
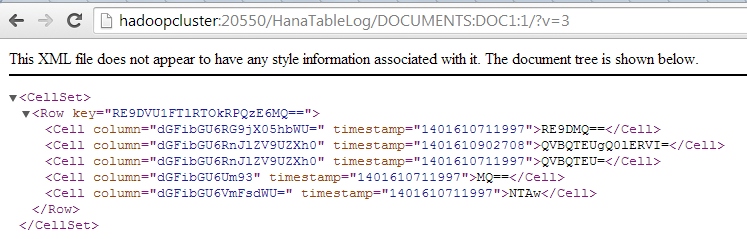
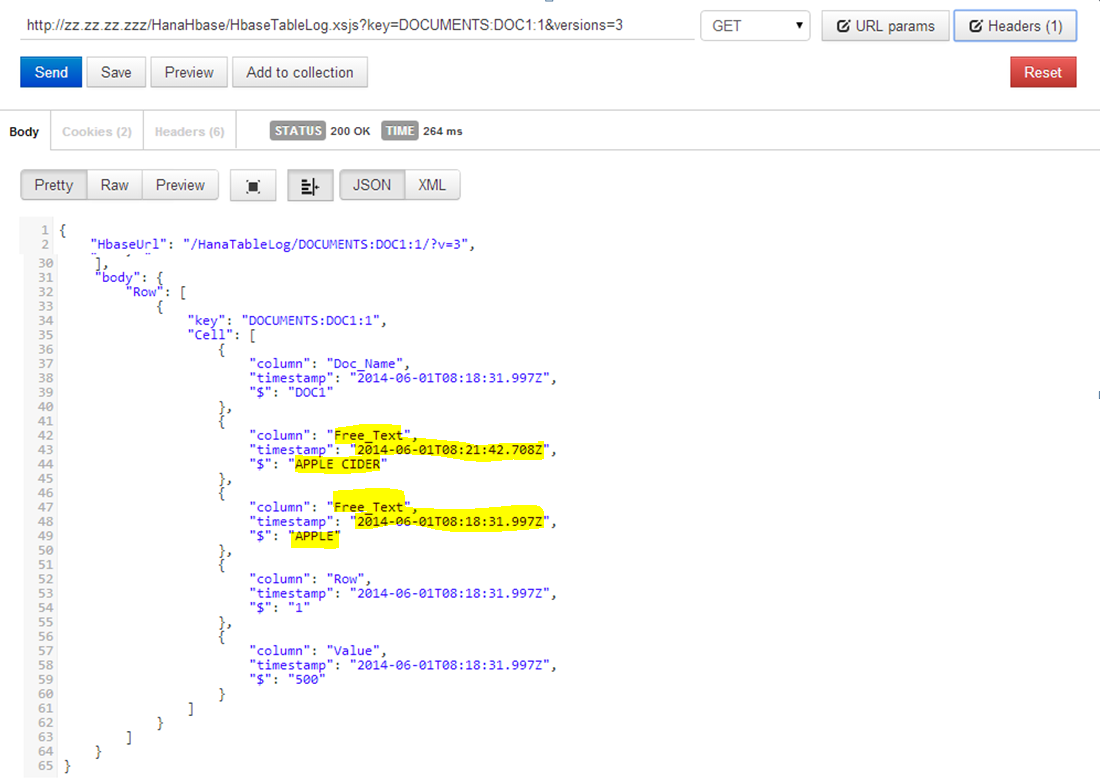
In this third part of the BlogProject, we will see how to create the data model so that we can manage and analyze our data in a more robust manner and add our application logic on top of the data.
If you missed the previous posts about the creation of an XS project and the persistence model (especially the data schema in the 2nd part) make sure to have a look:
http://scn.sap.com/community/developer-center/hana/blog/2014/05/27/introduction-to-hana-xs-application-development-part-1-blogproject-creation
http://scn.sap.com/community/developer-center/hana/blog/2014/05/27/introduction-to-hana-xs-application-development-part-2-blogproject-persistence-model
The modeling components that HANA provides are SQL views and information views. Of course HANA provides the capabilities of the standard SQL views. But what seems to be the most interesting part of HANA modeling are information views. When we talk about information views, we refer to the three types of views: attribute views, analytic views and calculation views. These views are non-materialized, leading to increased agility and less storage requirements.
![info views.png]()
Image 1: Information views architecture
Information Views
Attribute views
Attribute views are dimensions, BW characteristics or master data (mostly) and are used to join dimensions or other attribute views, creating logical entities (like Product, Employee, Business Partner) based on multiple objects. However, if the needs of the use case require it, attribute views can be created on transaction data too. Attribute views are re-usable and often shared in Analytic and Calculation Views. Lastly, attribute views include only attribute, and not measure, columns, and user defined calculated columns that use certain functions on attribute columns.
Analytic views
Analytic views are thought of as OLAP views, representing star schemas, where one or more fact tables are surrounded by dimensions. Analytic views are used for multidimensional data analysis and cube queries. They are typically defined on at least one fact table, that contains transactional data, along with a number of tables or attribute views, that play the role of dimensions to the fact table(s). In addition, in this type of views, you can define calculated columns based on other columns, or restricted columns, which enable you to filter the data on certain columns. Except from that, there is the capability of adding input parameters and variables, to affect the result of the view. Furthermore, except from attribute columns, an analytic view can contained measures, which can be aggregated.
Calculation views
Calculation views are composite views used on top of analytical and attribute views, as indicated by Image 1, used to perform more complex calculations not possible with other views. They are usually used when working with multiple fact tables, or when Joins are not sufficient. They can use any combination of any number of tables, attribute and analytic views, using union, join, aggregation and projection operators. A calculation view can be defined in a graphical manner, which is usually the case, producing graphical calculation views, or in a scripted manner with the use of SQL Script, producing scripted calculation views. Lastly, a calculation view allows the definition of attributes and measures, as well as the creation of calculated and restricted columns and input parameters and variables.
When to use each view
Searching the web and communities, I found the below picture that contains the whole concept of the data analysis in HANA and what component to use, depending on the requirements of your application. In this part we will deal only with the information views, leaving the scripting methods for later analysis.
![HANA analyze.png]()
Image 2: Information views usage
Information views and BlogProject
In our use case we will only use attribute views for joining our master data tables and calculation views to provide multiple joins and aggregations. We will not use analytic views because in this particular application the data do not require a star schema representation. In fact what we want to do here is create collections of attributes, measures, calculations and aggregations that will be exposed to the user interface and provide the data that a user will need. So, if we think about it, what a user wants (in fact what we want our user to want) is to read and write posts, read and write comments, see his/her profile and see country statistics.
![all views.png]()
Create attribute views
First we will create the comment entity that we want to expose to a user. First of all the user must see the text of the comment, the date and the user that wrote it. If we consider creating a profile screen for the user, then his/her comments will also be shown there, but it would be great for the user to be able to see the corresponding post of a certain comment, too.
So, in the below attribute view we join the tables POST and USER with the COMMENT in the columns that play the roles of foreign keys. We keep both the ID and name(Username, PostTitle) columns because it is easier for as to manage ids, but easier for the user to manage names.
To create this view you have to drag your mouse from the foreign key to the primary key, for example from COMMENT.UserID to USER.ID, and then choose the type of join and cardinality from the properties to the right down side. In this case we have chosen “referential” join with cardinality 1(USER, POST) to many (COMMENT).
![AT_COMMENT.png]()
For the central entity, the POST, and following the previous logic, we want to show to the user not the UserID, but the Username. So, same as before we drag from the foreign to the primary key, choose from the properties “referential” join and 1(USER) to many(POST) cardinality. Again we keep the UserID for our own purpose. Then, we have to add to the output the columns we want by clicking on the sphere next to each column.
![AT_POST.png]()
In this example we extend our attribute view logic by adding a Calculated Column. Let’s say we want a column to give as a clue about a post’s popularity, except from Views. To do that we will create a column called LikesDislikesRatio, by pressing right click on the Calculated Columns folder, choose “New” and follow the wizard. The formula is simple, it’s the fraction Likes/Dislikes. Let’s make the convention that when Dislikes are zero(0) then the result will be the number of Likes, and when the Likes are zero(0) the result will be zero(0), given that we only care for the most popular.
Create calculation views
We could keep on creating attribute views, but at some points we will need some aggregations. In our case we want to know how many comments are written for a single post, how many incoming links there are for this post, the number of posts and comments written by a certain user and how many posts are made in the country level.
Let’s start with the POST. We would like to count the number of comments and inbound links for each post. To do so we follow the procedure shown below.
First, we have to join each COMMENT with the corresponding POST. For the post entity we use the attribute view AT_POST we created previously, that holds the additional information we wanted. To join, after we have created a join (JOIN_1) and added the 2 objects, we drag the mouse from COMMENT.PostID to AT_POST.ID and we choose cardinality 1(AT_POST) to many(COMMENT). In contrast to the joins we made in the attribute views, now we will choose Left Outer join, because we want to keep all the rows of the AT_POST, even those that don’t have comments or links.
![CALC_POST(Join_1).png]()
As a result we have for each post, the ids of all its comments.
Then, we will create another join (JOIN_2) to join the previous join (JOIN_1) with the POST2POST table. Again, we drag the mouse, choose cardinality 1 to 1 and change the join type to Right Outer, because we want in the result all the columns and not only the ones that exist in both tables.
![CALC_POST(Join_2).png]()
Doing this, we added to each post the ids of the posts that have outbound links.
The next step is to actually create the aggregations. To do this we have to connect our last join (JOIN_2) to the Aggregation operator. In the Aggregation, we will create our two aggregated columns that will hold the number of comments and incoming links for each post. We simply right-click on the Calculated Columns folder, but this time we choose “New counter” and follow the wizard choosing which column we want to count. We do this twice, creating the two columns “CommentsNo” and “InLinks”.
![CALC_POST(Aggregation).png]()
For the Country entity we will follow the same procedure, first joining the country with the user, then the result of the join with the post. In the properties we can see the details of each join.
![CALC_COUNTRY(Join 1).png]()
![CALC_COUNTRY(Join 2).png]()
The result is for each country all the user ids and for each user id the post ids that the user has written.
Then, in the Aggregation operator, we create again two new counter, counting the number of posts and the number of users for each country.
![CALC_COUNTRY(Aggregation).png]()
Lastly, we want to create a view that holds all the important information about a user. In addition, we want to know for each user how many posts and comments he/she has written.
Again following a similar procedure, at the beginning we join the USER with the COUNTRY, to replace the countryID with actual name of the country.
![CALC_USER(Join 1).png]()
Then, we join the result with the POST table to get the postIDs of each user’s post.
![CALC_USER(Join 2).png]()
After we have joined the JOIN_1 with the POST, we join the resulted JOIN_2 with the COMMENT table to get the commentIDs of each user’s comments.
![CALC_USER(Join 3).png]()
Lastly, we create the two columns (Counters) that will hold the number of posts(PostsNo) and comments(CommentsNo) of each user. The properties tab shows the details.
![CALC_USER(Aggregation).png]()
Having done all the previous procedures, we have completed our data model and we are ready to expose it to our ui application. The data will be exposed with OData protocol and more specifically via a number of OData services in the next post.
Hope you enjoyed!!